
Single Leader Database Replication - Part I


I have been always curious how database replication actually works. Database replication actually helps in keeping a copy of your database so that when the thunder falls your users data is safe. It also helps in keeping your database geographically close to your users and to scale your machines so that you can serve read queries to large number of users.
If the data in your database does not change often than your problem is already solved , you can replicate your database once a day and you are good to go, but if your data changes very frequently then the real problem arises. That’s what we are going to tackle in this blog. We will see three most popular algorithms for database replication :
Single Leader Replication
Multi Leader Replication
Leaderless replication
All databases use one of these approaches , which we will see and all have there own pros and cons.
There are many trade offs to consider with database replication like synchronous or asynchronous and how to handle failed replicas. Replication of database is an old topic and the main principles haven’t changed much since 1971 because fundamental constraints of network have remained the same.
Leaders and Followers
Node that stores a copy of data is called replica. Every write operation (insert, delete or update) that happens to your main database should also be executed on your replica databases otherwise your replicas will not be in sync with your main database. Most common architecture is leader based replication(active/passive or master/slave). It works as follows:
Every write operation that client performs goes directly to leader database, it executes the query and updates the data in its local storage.
Once leader database is updated, it sends the queries in the same order that they were executed to secondary(slaves or passive) databases.
When a client wants to read from the database, it can query any of the replicas and can get the updated data. However writes are only accepted on the leader(followers are read only).
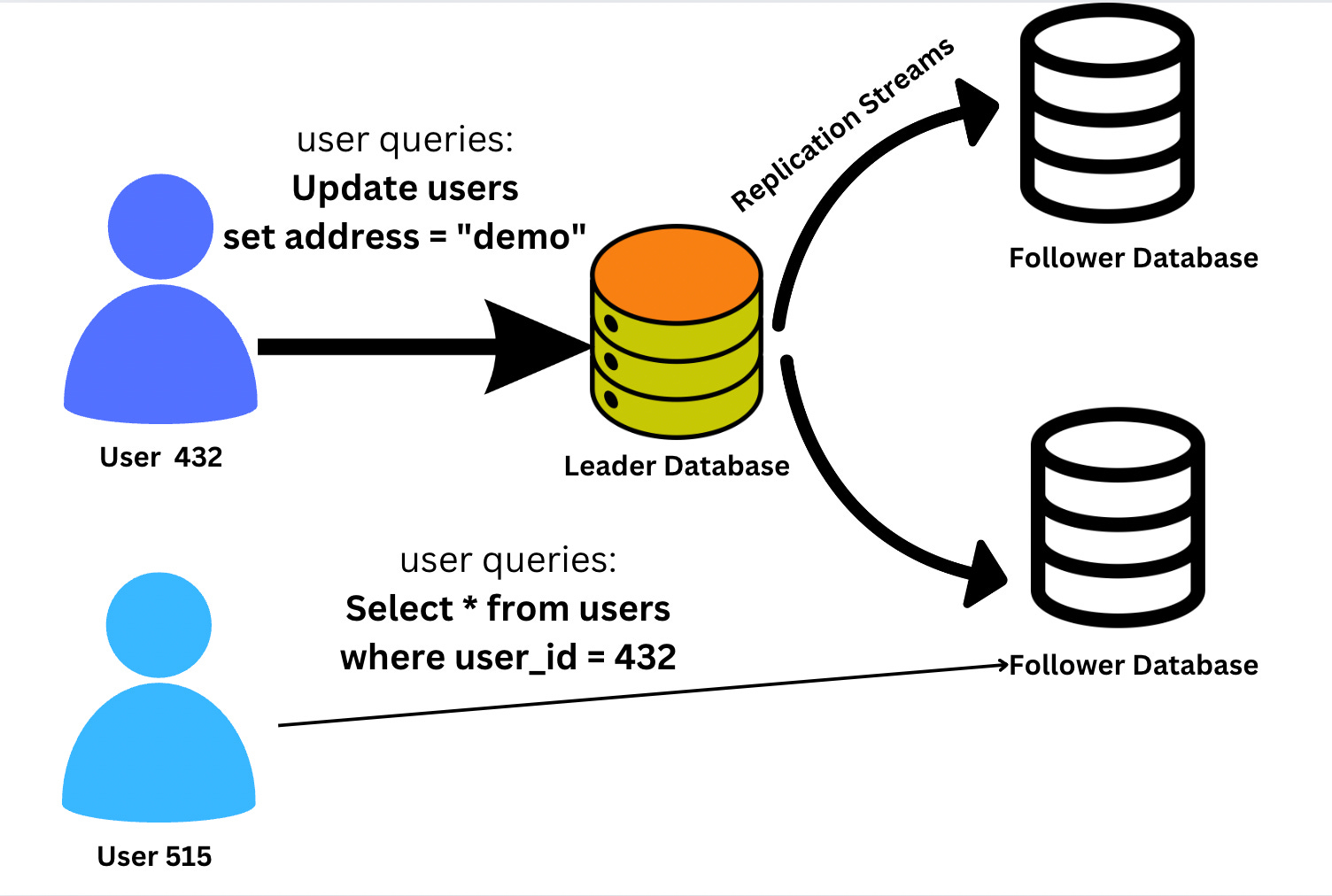
Leader based replication is not just restricted to sql databases it is also used by some nosql databases like MongoDB and RethinkDB. There are some highly message brokers like kafka and rabbitMq also uses it.
Synchronous Vs Asynchronous Replications
A very important factor in replicated system is wether it is synchronous or asynchronous. Databases gives configuration options to change that, but there are other system who have hard coded it.
When a user sends a write operation on your leader database, it executes the query and than sends the query to its followers and once they are updated , user is notified that data was saved.
For example see in the diagram below, leaders sends the query to its follower and once it has updated it notifies client that query was successful, here our leader database didn’t wait for the result from second follower. So, we can say that follower 1 is synchronous replication and follower 2 is asynchronous.
Note: In below figure time is increasing from left to right
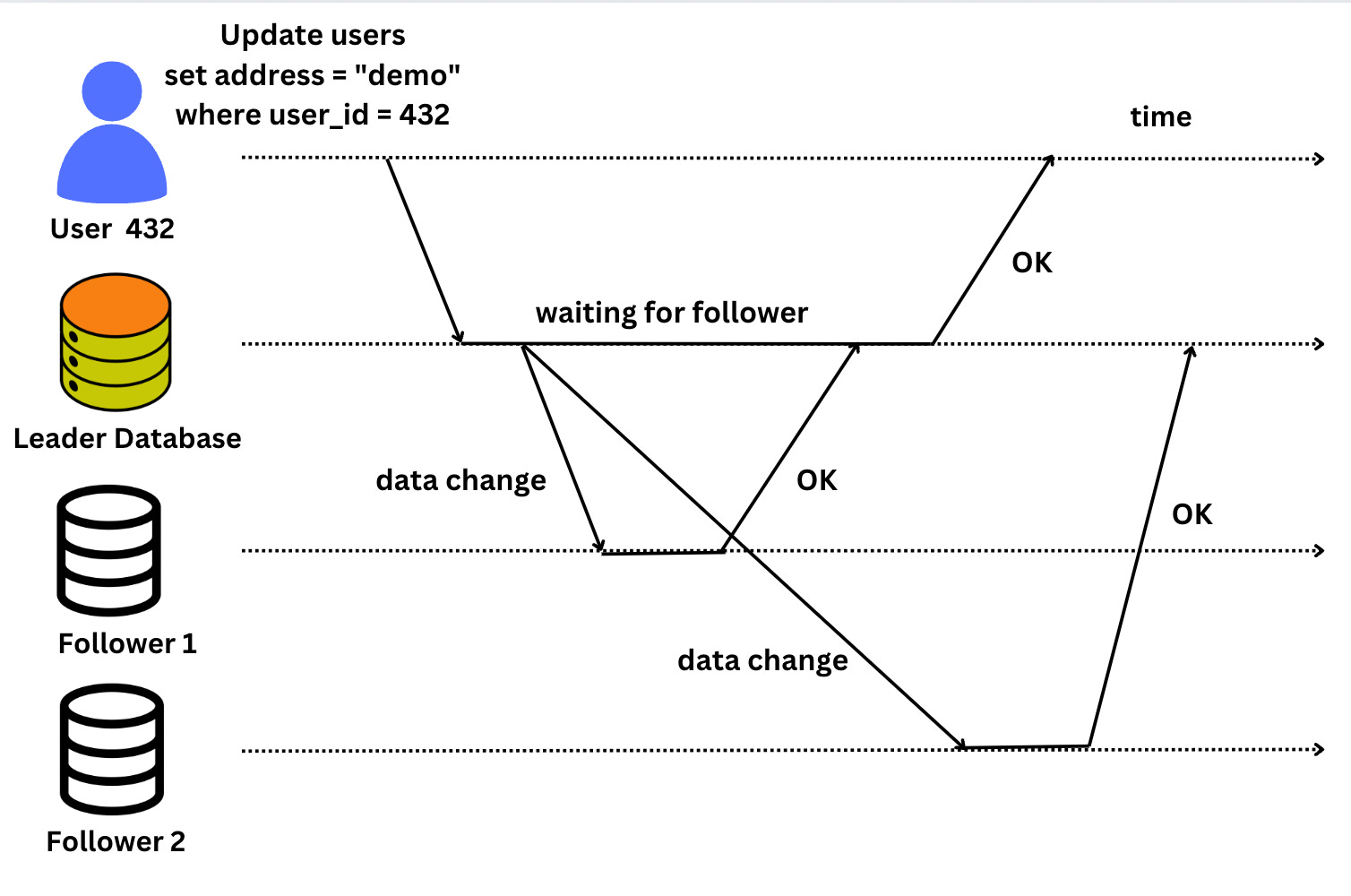
Since, we can see here that follower 2 took long time to update, but it didn’t affected the user because it was our async replica.
The advantage of having a synchronous replica is that you have an up-to-date database that can immediately take over if the leader database fails. However, the disadvantage is that if your synchronous replica goes down, your leader database will be stuck waiting for it to come back online. This is why it's not practical to have all your followers as synchronous replicas. In practice, enabling synchronous replication usually means having one synchronous replica while others remain asynchronous. If the synchronous replica slows down, one of the asynchronous replicas is promoted to synchronous status. This setup—with a leader and one synchronous follower—is called semi-synchronous replication.
Advantage of having fully asynchronous replicas is, the leader can continue accepting writes even if its replicas have fallen behind, but the disadvantage is if leader database goes down and the latest write has been confirmed to user but not to async replicas, it means changes will be lost.
It may look like asynchronous replication is not very reliable but you would be amazed to know that this is most widely used specially when the databases are located geographically distant. We will come to this later.
Setting Up New Followers
There are times when you have to increase your replica nodes, or replace it with your failed nodes. To set up new follower, we have to ensure that it has up to date data with leader node. If we just try to copy the data to follower node, it will not be accurate becomes our leader node is continuously accepting writes, so a standard copy would see different parts of data at different times. You could argue that , let’s apply a lock on leader database so that its data does not get updated and then do the copy, but that would bring down availability of our system.
You would be happy to know that databases have a way to do it, without affecting the availability. The process looks like this:
Take a consistent snapshot of the database at some point in time, if possible without taking a lock on the database.
Copy the snapshot to the new follower
Once the snapshot is loaded in the new follower database, follower database request to leader node to provide with all the data that was written since the snapshot was taken. Once follower node has got that data, it is said to be caught up. The position at which snapshot was taken has various names given by databases, postgres call it log sequence number and Mysql calls it the binlog coordinates.
Now since your follower has caught up, it can start accepting data.
Handling Node Outages
It is not unusual for any node to go down, it can be due to network failure or some scheduled maintenance. We need to make sure that when node outage happens, our system is running without being affected by it. So, how do we achieve high availability in leader-based replication ?
Follower Failure: Catchup Recovery
Follower node stores a log file of data that it has received from leader node. Whenever follower node is interrupted due to any of the reason it can recover very easily with the help of the log file. It requests leader node to provide all the data since last log data that he already has. Once follower node has caught up, it can resume its normal operation of accepting data streams.
Leader Failure: Failover
Handling leader node failure is tricky, you have to do the following:
One of the follower node is promoted to be the leader
Client is reconfigured to send writes to new leader
Other follower should now accept writes from new leader
Failover can be manual or automatic. Automatic failover has the following process:
Determine leader has failed: Leader can fail due to various reasons like network issue, natural disaster or anything. We can never be always sure of the reason, usually a hear beat is sent for every 30 seconds or so and if node does not respond it is considered to be failed.
Choosing a new leader: There are some ways to choose a new leader
It can be done by election process (chosen by remaining replicas)
New leader could be appointed by previously elected controller node
The best candidate is , the replica which has the most up to date data to minimise data loss. Getting all nodes to agree on a new leader is a consensus problem (will discuss later)
Reconfigure client to use new leader: Clients now need to send write request to new leader and also when old leader comes back it might still think its the leader that could create discrepancies so we need to ensure that old recognises new leader.
Failover has many things that could go wrong:
If you have asynchronous replication, your leader goes down but by that time it had received some writes which were not able to be sent to followers. Now one of the follower is promoted to leader and it had also received some writes, and now your old leader comes back. Old leader has writes which are not any other system, and best way to handle this is to discard those writes from old leader, which may violates client’s durability (become earlier client already got a response that his write was successful).
Discarding writes is always dangerous especially when other database systems needs to be coordinated with database contents. For example an incident happened at Github, an outdated follower was promoted to leader. Since the new leader re-utilised some primary keys which have already been used by old leader and those keys were also already in use in redis database. This lead to disclosing private information of some users.
In certain situations it may happen that two nodes may believe that they are the leader nodes this is called split brain. There are systems to detect so that we have only one leader at a time and if there are two then remove one of them while taking care that not both of them are removed.
What would be the right timeout to consider the leader dead. If we keep longer timeouts, it will lead to longer recovery time and shorter timeouts can give false dead information, because if a leader node is facing high traffic and doing a failover at that time will just make the situation worse.
So, you see doing failover is not easy thing there are n number of things that can go wrong that’s why companies usually prefer manual failovers.
These issues node failures, unreliable networks and trade offs around replica consistency, durability, availability and latency are in-fact the fundamental problems of distributed systems
Implementation of Replication Logs
How does leader based replication actually happen, will look into this now.
Statement based replication
In statement based replication leader node, sends UPDATE, DELETE and INSERT query that it executes directly towards its followers nodes so that they can run the query as it is. Although it sound simple and reliable, but there are some issues with it like :
If your query contains non-deterministic functions like RAND it can produce different values every time the query is run. So this can lead to different values on different nodes.
If the statements uses auto-incrementing column or if they depend on existing data in the database (UPDATE … WHERE <some condition>) **in this case queries needs to be executed in the same order as it ran on leader nodes otherwise it will produce different results.
Statements that have side effects (e.g, user defined functions) may result in different side effects occurring on different machines if the functions side effects are not absolutely deterministic.
Although you can take care of non-deterministic functions by replacing the functions like RAND with actual values when the statement is logged. But there are many edge cases due to which other methods are used for replication.
Write ahead Log(WAL) shipping
In our previous blog we discussed how storage engines represent data on disks and we say that every write is usually appended to log:
In case of log structured storage engines (SSTables and LSM tree) this log is the main place of storage. Log segments are compacted and garbage collected in background.
In case of a B-tree which overwrites individual disk blocks, every modification is first written to a write-head log so that index can be restored after a crash.
In either case log is an append only sequence of bytes which is maintained by database, leader node after writing to log file also sends to across the network to its followers and follower nodes can use this log to reconstruct the database with exact same data as on leader node.
This method of replication is used in PostgreSql and Oracle. One of the main disadvantage of this method is WAL maintains this log at very low level. WAL contains which bytes were changes in which disk blocks. This makes replication closely coupled to storage engine. If database changes its storage format from one version to another in that case your leader and follower node cannot operate on different software version they will always need to be on the same version.
This drawback has big operational impact, if replication protocol allows followers to use new software version you can zero-downtime upgrade by updating the followers version and then doing failover on leader node, but if replication protocol does not allow followers to use new version in that case you will have some downtime to upgrade.
Logical (row based) replication
Logical log for relational database is a sequence of records describing writes to database at the level of row:
For an inserted row, all columns values are stored in the log.
For a deleted row, primary key of the record is stored to identify that it is deleted and if table does not have a primary key than all column values are stored to identify that row.
For updated row, log contains information to uniquely identify the row and new values to update them.
Such logical log storage is loosely coupled from the storage engine and can be easily be kept to be backward compatible so that leader and followers of different software versions can even run this logs.
Trigger based replication
Till now the replication strategy discussed are implemented by database systems internally and no application code is used, but there are cases where you need flexibility like you only need to copy a subset of data or copy from one type of database to another. To handle these cases you need to write some application code. Tools such as Oracle Golden gate can make data changes available to application code. An alternative approach is to use features available in relational databases triggers and stores procedures. A trigger lets you register custom application code which is executed when a data change happens and you can write logic to copy that data in a separate table. Which from there can be read by external process. Trigger based replication has overheads and are prone to bugs then other replication based approach. But are certainly useful in some cases.
Conclusion
We have covered some decent amount of topics in this blog, we saw types of database replication, synchronous and asynchronous replication, handling node outages and implementing replication logs. This is a vast topic and will release more parts in the serious to cover database replication in detail. In coming parts will see problems with replication lag, how to tackle and multi leader replication. Till then keep learning.
References
Design Data Intensive Application by Martin - Chapter 5.